


PDFlux是一個強大的文檔內容提取軟件,可以從PDF中提取出想要的各種內容,包括表格、段落、圖片、圖表等等,通過OCR識別來精確選取提取的數據,提取后仍然能夠保持規范的排版。支持目錄一鍵生成功能,導入PDF即可智能生成合適的目錄,還有識別翻譯、印章提取等功能待你體驗。
PDFlux使用技巧
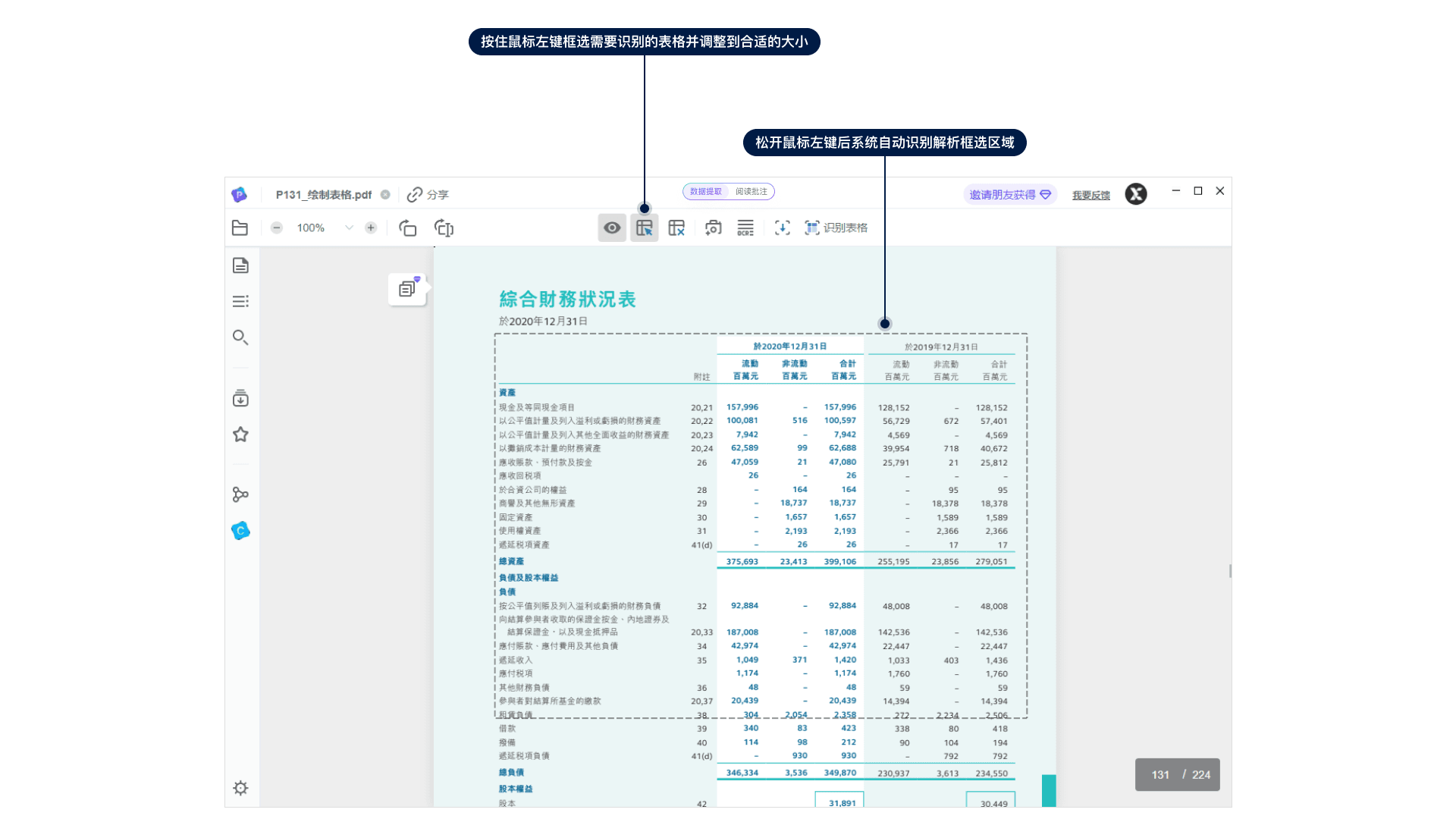
如何識別文檔內表格?
答:文檔詳情頁面,點擊頂部工具欄“識別表格”按鈕,PDFlux將自動識別本頁的表格和其它元素。

如何解決未能自動識別的表格?
您可以通過頂部工具欄,手動框選表格區域,PDFlux將自動識別表格內線。框選區域越精準,識別效果越佳。您還可以同屏比對、手動調整、一鍵刪除空格和換行,得到更好的識別結果。
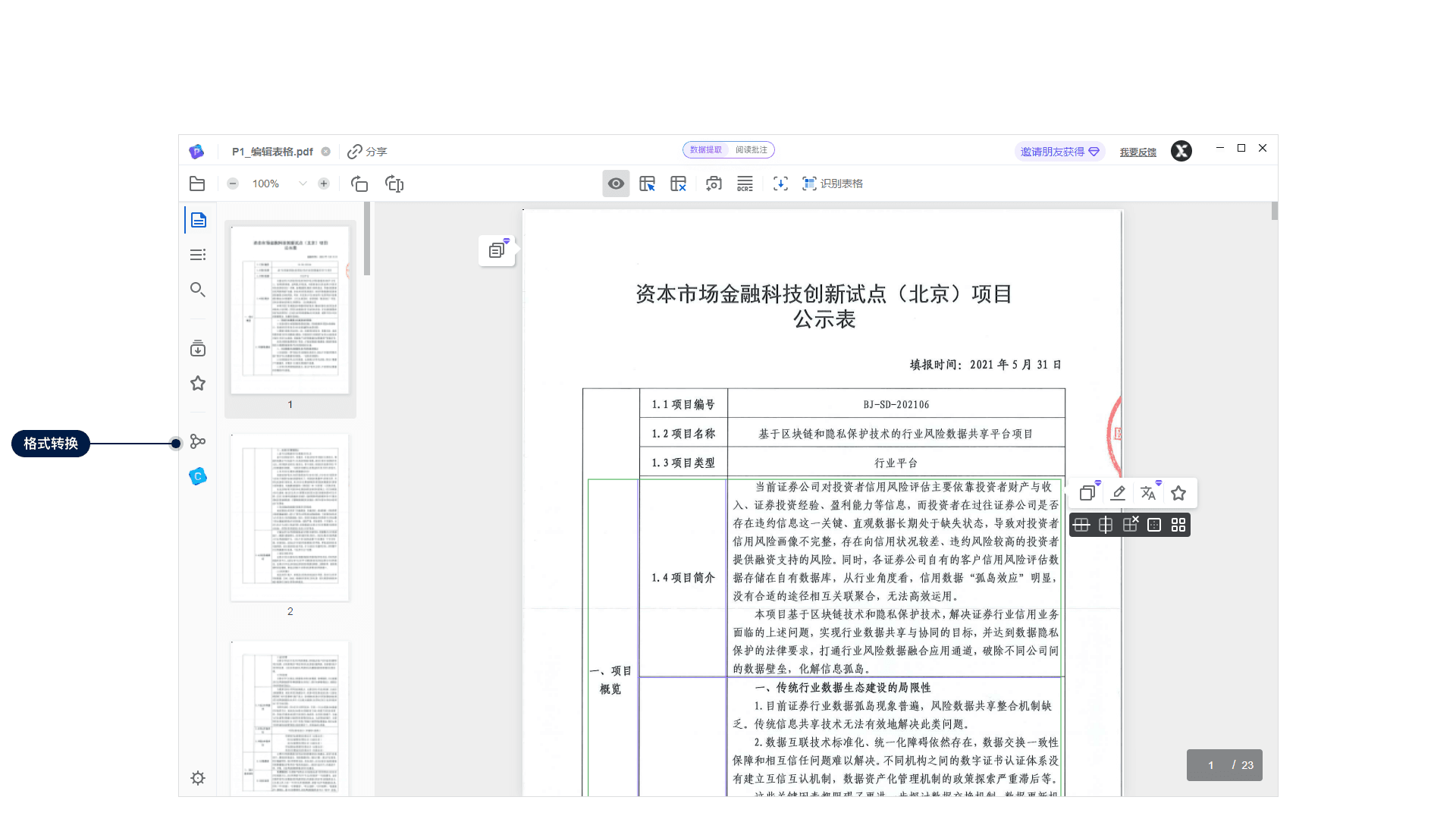
如何轉換文檔格式?
點擊左側工具欄格式轉換圖標,進入格式轉換頁面,支持PDF轉化為Word、Excel、Html等多種格式。
PDFlux常見問題
1、問:PDFlux在什么樣的背景下誕生?
答:隨著大數據、云計算、區塊鏈和人工智能等前沿技術的不斷迭代和適用革新,金融科技已經開始賦能傳統金融產業的業務轉型,借助金融科技優化現有商業模式效率、改善客戶體驗已成為全球商業社會的大趨勢。 復雜排版表格的自動分析作為人工智能的一項重要技術分支,可以實現從海量的數據文檔中,提取有線框表格及復雜排版表格的功能,大大提高金融分析師的工作效率,該技術支持智能投研、智能風控等細分垂直領域場景的應用。
2、問:PDFlux有什么特性?
答:PDFlux 可高精度識別提取 PDF / 圖片 / 掃描件中的表格和文本,通過特殊場景和行業文檔的強化訓練,模糊掃描、水印干擾、無框線表格也能精準識別,表格提取的準確率可達到 99%,尤其擅長財務報表的提取。基于深度學習技術解析文檔結構,讓 PDF 的內容像 Word 一樣易于復制,表格行列工整,文本無亂碼,大幅減少非結構化數據轉化中的損耗。目前 PDFlux 提供私有化部署服務及 SaaS 私有云服務(toB),以及 PDFlux 客戶端、Web 版、小程序版(toC、供客戶體驗為主)。
3、問:什么是OCR?
答:OCR(Optical Character Recognition),意為光學字符識別,或文字識別。文字識別,是對文本資料進行掃描,再對圖像文件進行分析處理,最終獲取文字及版面信息的過程。通俗理解,舉個例子:就是把圖片或PDF里的文字信息進行抓取,轉換成Word、TXT等可以編輯的文本文字。
4、問:OCR不能識別的原因有哪些?
答:OCR 不能識別,往往是由于提取圖片信息失敗,無法提取證件上的文字信息上傳。OCR 識別技術無法保證100%識別成功、識別正確,只能無限接近于100%,遇到這種情況屬正常現象,可以選擇手動錄入。 OCR文字識別是指電子設備(例如掃描儀或數碼相機)檢查紙上打印的字符,然后用字符識別方法將形狀翻譯成計算機文字的過程;即,對文本資料進行掃描,然后對圖像文件進行分析處理,獲取文字及版面信息的過程。如何除錯或利用輔助信息提高識別正確率,是OCR最重要的課題。衡量一個OCR系統性能好壞的主要指標有:拒識率、誤識率、識別速度、用戶界面的友好性,產品的穩定性,易用性及可行性等。
5、問:什么是FinOCR?
答:掃描件或圖片的識別效果,是由OCR的質量決定的。庖丁科技自主研發的 FinOCR ,具有業界領先的識別精度。FinOCR 充分結合了用戶的使用場景并深度結合 PDFlux 中的文檔結構識別、表格外線和內線結構識別等AI模型,針對金融場景中占比較多的低分辨率、有印章等干擾因素的掃描件,都進行了專門的優化,可以高效地識別模糊以及含有涂寫、水印等干擾因素的文檔。
PDFlux功能特點
表格智能提取
無線表格,智能識別
復雜排版,精確提取
表格歪斜,自動扶正
印章干擾,輕松搞定
跨頁表格,智能合并
空格換行,一鍵去除
OCR 精準識別
模糊掃描,強化修復
框選印章,提取印文
框選段落,提取文字
框選表格,繪制框線
框選圖片,截圖復制
整頁內容,批量提取
高級解析功能
章節目錄,一鍵生成
識別翻譯,中英互譯
財務報表,規范導出
PDFlux軟件優勢
多種格式,自由轉換
將 PDF 轉化為 Word、Excel、HTML 等格式,方便進行編輯
將 PDF 轉化為 EPUB、MOBI 等電子書格式,方便移動端閱讀
精準劃分文本段落、表格等內容信息
精準識別并保留文檔的章節目錄結構
協同批注,在線分享
多人批注溝通,PDF 也能輕松協同
批注實時同步,信息傳遞無時差
一鍵分享文檔,點擊鏈接即開即用
文檔鏈接加密,確保數據安全無虞
上一篇:福昕PDF編輯器個人版
下一篇:PDFsam Basic中文版
 360解壓縮軟件2023
360解壓縮軟件2023 看圖王2345下載|2345看圖王電腦版 v10.9官方免費版
看圖王2345下載|2345看圖王電腦版 v10.9官方免費版 WPS Office 2019免費辦公軟件
WPS Office 2019免費辦公軟件 QQ瀏覽器2023 v11.5綠色版精簡版(去廣告純凈版)
QQ瀏覽器2023 v11.5綠色版精簡版(去廣告純凈版) 下載酷我音樂盒2023
下載酷我音樂盒2023 酷狗音樂播放器|酷狗音樂下載安裝 V2023官方版
酷狗音樂播放器|酷狗音樂下載安裝 V2023官方版 360驅動大師離線版|360驅動大師網卡版官方下載 v2023
360驅動大師離線版|360驅動大師網卡版官方下載 v2023 【360極速瀏覽器】 360瀏覽器極速版(360急速瀏覽器) V2023正式版
【360極速瀏覽器】 360瀏覽器極速版(360急速瀏覽器) V2023正式版 【360瀏覽器】360安全瀏覽器下載 官方免費版2023 v14.1.1012.0
【360瀏覽器】360安全瀏覽器下載 官方免費版2023 v14.1.1012.0 【優酷下載】優酷播放器_優酷客戶端 2019官方最新版
【優酷下載】優酷播放器_優酷客戶端 2019官方最新版 騰訊視頻播放器2023官方版
騰訊視頻播放器2023官方版 【下載愛奇藝播放器】愛奇藝視頻播放器電腦版 2022官方版
【下載愛奇藝播放器】愛奇藝視頻播放器電腦版 2022官方版 2345加速瀏覽器(安全版) V10.27.0官方最新版
2345加速瀏覽器(安全版) V10.27.0官方最新版 【QQ電腦管家】騰訊電腦管家官方最新版 2024
【QQ電腦管家】騰訊電腦管家官方最新版 2024 360安全衛士下載【360衛士官方最新版】2023_v14.0
360安全衛士下載【360衛士官方最新版】2023_v14.0