


IBM SPSS Statistics是一款專業的統計分析軟件,這款強大的綜合分析軟件將為用戶帶來更加快速、有效和深入的數據挖掘功能,被廣泛應用于統計學分析運算、數據挖掘、預測分析和決策,是全球領先的大數據統計分析和數據挖掘軟件,它比電子表格、數據庫或標準多維工具更加的實用和方便。是公認的最優秀的統計分析軟件包之一!廣泛應用于通訊、醫療、銀行、證券、保險、制造、商業、 市場研究、科研教育等多個領域和行業。winwin7給大家帶來的IBM SPSS Statistics 26.0為中文破解版,完全免費使用!
IBM SPSS Statistics安裝教程
1、雙擊SS_CLIENT_64-BIT_26.0_M_W_M.exe運行,見下圖所示:

2、下一步,見下圖所示:

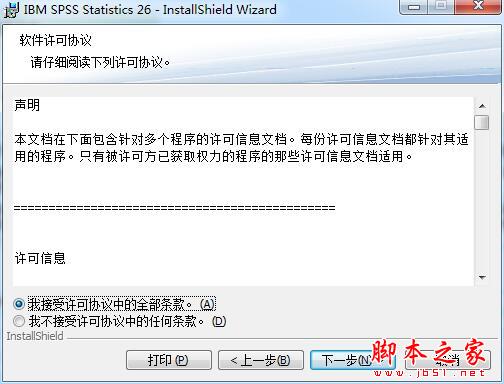
3、同意許可協議,見下圖所示:
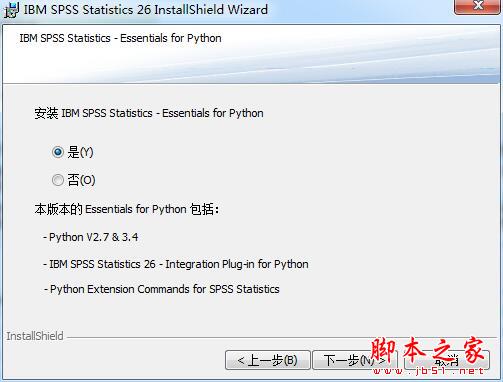
4、是否安裝Esseontials for Python,見下圖所示:
5、再次接受許可協議,見下圖所示:
6、選擇安裝路徑,見下圖所示:
7、點擊安裝即可,見下圖所示:

8、安裝完成,見下圖所示:
9、復制crack破解文件下的許可證文件“lservrc”到軟件安裝目錄下
默認安裝路徑【C:\Program Files\IBM\SPSS\Statistics\26】,見下圖所示:

使用幫助
一、數據文件
數據文件有多種格式,而本軟件被設計為可以處理其中的許多格式,包括:
Excel電子表格
來自許多數據庫源(包括Oracle、SQLServer、DB2等等)的數據庫表
制表符分隔類型、CSV類型和其他類型的簡單文本文件
SAS數據文件
Stata數據文件
1、打開數據文件
除了以 IBM® SPSS® Statistics 格式保存的文件以外,還可以打開 Excel、SAS、Stata、制表符分隔文件和其他文件,而無需將文件轉換為中間格式或輸入數據定義信息。
打開數據文件會使其成為活動數據集。如果已經打開了一個或多個數據文件,則它們將保持打開狀態,并可在以后的會話中使用。單擊“數據編輯器”窗口中的任意位置會使打開的數據文件成為活動數據集。請參閱使用多數據源主題以獲取更多信息。
在分布式分析中,使用遠程服務器處理命令和運行過程的模式、可用的數據文件、文件夾和驅動器取決于遠程服務器上可用的內容。當前服務器名稱在對話框的頂部指明。除非將驅動器指定為共享設備,或者將包含數據文件的文件夾指定為共享文件夾,否則將不能訪問
從菜單中選擇:
文件 > 打開 > 數據...
在“打開數據”對話框中,選擇要打開的文件。
單擊打開。
根據需要,您可以:
根據觀察值,最小化字符串寬度將每個字符串變量寬度自動設置為該變量的最長觀察值。在 Unicode 方式下讀取代碼頁數據文件時特別有用。請參閱一般選項主題以獲取更多信息。
從電子表格文件的第一行讀取變量名稱。
指定電子表格文件中要讀取的單元格范圍。
指定 Excel 文件中要讀取的工作表(Excel 95 或更高版本)。
2、數據文件類型
SPSS Statistics。打開以 IBM® SPSS® Statistics 格式保存的數據文件以及 DOS 產品 SPSS/PC+。
SPSSStatistics 壓縮。打開以 IBM SPSS Statistics 壓縮格式保存的數據文件。
SPSS/PC+。 打開 SPSS/PC+ 數據文件。此選項只在 Windows 操作系統中可用。
便攜。 打開以可移植格式保存的數據文件。以可移植格式保存文件比以 IBM SPSS Statistics 格式保存文件所耗費的時間要長得多。
Excel。 打開 Excel 文件。
Lotus 1-2-3。 打開以 1-2-3 格式(對于 Lotus R3.0、2.0 或 1A)保存的數據文件。
SYLK。 打開以 SYLK(符號鏈接)格式保存的數據文件,SYLK 格式是部分電子表格應用程序所使用的格式。
dBASE。 打開 dBASE 格式文件(dBASE IV、dBASE III 或 III PLUS 或者 dBASE II)。每個個案均是一條記錄。當您以這種格式保存文件時,變量和值標簽以及缺失值的指定會丟失。
SAS。 SAS V6 - V9 和 SAS 傳輸文件。使用命令語法,您還可以從 SAS 格式目錄文件中讀取值標簽。
Stata。 Stata V4 - V14(Stata 14 支持 Unicode 數據)。
3、讀取Excel文件
本主題適用于 Excel 95 和更高版本文件。要讀取 Excel 4 或更低版本,請參閱主題讀取舊 Excel 文件和其他電子表格。
工作表
Excel 文件可以包含多個工作表。缺省情況下,數據編輯器讀取第一張工作表。要讀取其它工作表,請從列表中選擇工作表。
范圍(R)
也可以讀取某個范圍的單元格。請使用與在 Excel 中相同的方法指定單元格范圍。例如:A1:D10。
從第一行數據讀取變量名稱
可以從文件的第一行或所定義的范圍的第一行讀取變量名稱。不符合變量命名規則的值會轉換為有效的變量名稱,原始名稱將用作變量標簽。
用于確定數據類型的值的百分比
每個變量的數據類型由符合相同格式的值的百分比確定。
值必須大于 50。
用于確定百分比的分母為每個變量的非空值的數目。
如果指定百分比的值使用了不一致格式,那么會為變量指定字符串數據類型。
如果基于百分比值為變量指定了數字格式(包括日期和時間格式),那么會為不符合此格式的值指定系統缺失的值。
忽略隱藏的行和列
不會包含 Excel 文件中隱藏的行和列。此選項僅適用于 Excel 2007 和更高版本的文件(XLSX 和 XLSM)。
從字符串值移除前導空格
將移除字符串值開頭的任何空格。
從字符串值移除尾部空格
將移除字符串值尾部的空格。此設置影響字符串變量的定義寬度的計算。
數據編輯器
數據編輯器提供一種類似電子表格的便利方法來創建和編輯數據文件。當您啟動會話時,“數據編輯器”窗口自動打開。
數據編輯器提供數據的兩種視圖:
數據視圖。 顯示實際的數據值或定義的值標簽。
變量視圖。 顯示變量定義信息,包括定義的變量標簽和值標簽、數據類型(例如,字符串、日期或數值)、測量級別(名義、序數或刻度)及用戶定義的缺失值。
功能特色
1、全方位的統計分析專用工具
在一體化的集成化頁面中工作中,運作描述統計、重歸分析、高端統計分析這些。在單一專用工具中就可以建立可馬上公布的數據圖表、表格和決策樹算法。
2、與開放源碼集成化
根據專業拓展,利用R和Python提高SPSSSyntax。利用大家的擴展中心給予的130多種拓展,或是搭建您自身的拓展并與同行業共享資源,以建立人性化解決方法。
3、輕輕松松開展統計分析分析
應用簡易的拖放頁面來瀏覽各種各樣作用,并跨好幾個數據源工作中。除此之外,靈便的布署選擇項適用您輕輕松松選購和管理系統軟件。
4、數據提前準備
輕輕松松鑒別失效值,查詢缺失數據的方式,歸納自變量遍布,并應用為為名特性設計方案的優化算法。
5、查詢標價并選購
建立更靠譜的實體模型,檢測其可靠性,并穩定地可能人口數量主要參數的標準誤差和可信區間。
6、高端統計數據
分析具備唯一特點的數據,敘述自變量和變量相互關系,并分析事情歷史數據和延續時間數據。
7、重歸
預測分析包括很多個類型的歸類結論,搭建最優控制關系模型,并從數十種概率中尋找最好預測分析自變量。
8、訂制表格
歸納有關數據,以演試品質的生產制造準備就緒型表格展現分析結論。您還能夠將最后另存到Microsoft?Office應用軟件中。
9、缺失值
查驗數據,發覺缺失的數據方式,隨后根據統計算法估計歸納統計分析并刀具半徑補償缺失值。
10、類型
形象化展現并探尋復雜性的歸類、數據和高維數據,并應用雙標圖、三標圖和認知圖來揭露潛藏的關聯。
11、繁雜樣版
根據將宣傳畫冊設計融進至調研分析中,測算繁雜宣傳畫冊設計中的統計數據和標準誤差。
12、協同分析
根據基于獨立的特征對購買者的管理決策步驟和使用價值開展模型,更確切地知道顧客的愛好、衡量選擇及價錢敏感度。
13、精確檢測
分析數據庫文件的偶發事件,或更確切地運用少許樣版。30多項精確檢測有利于分析造成傳統式檢測不成功的數據。
14、預測分析
無論數據集尺寸或自變量數量是多少,都能迅速穩定地預知未來情況,與此同時高效率地升級和管理方法預測模型。
15、決策樹算法
建立歸類和決策樹算法,協助您能夠更好地鑒別群聊、發覺每個群聊相互關系,并預知未來事情。
16、立即營銷推廣
實行近期選購時長、選購工作頻率和總購入額度(RFM)及群集分析、潛在用戶概述分析、郵編分析、共性得分和操縱包檢測。
17、神經元網絡
研究數據中細微或掩藏的方式,發覺數據中更繁雜的關聯,從而形成特性更好的預測模型。
 360解壓縮軟件2023
360解壓縮軟件2023 看圖王2345下載|2345看圖王電腦版 v10.9官方免費版
看圖王2345下載|2345看圖王電腦版 v10.9官方免費版 WPS Office 2019免費辦公軟件
WPS Office 2019免費辦公軟件 QQ瀏覽器2023 v11.5綠色版精簡版(去廣告純凈版)
QQ瀏覽器2023 v11.5綠色版精簡版(去廣告純凈版) 下載酷我音樂盒2023
下載酷我音樂盒2023 酷狗音樂播放器|酷狗音樂下載安裝 V2023官方版
酷狗音樂播放器|酷狗音樂下載安裝 V2023官方版 360驅動大師離線版|360驅動大師網卡版官方下載 v2023
360驅動大師離線版|360驅動大師網卡版官方下載 v2023 【360極速瀏覽器】 360瀏覽器極速版(360急速瀏覽器) V2023正式版
【360極速瀏覽器】 360瀏覽器極速版(360急速瀏覽器) V2023正式版 【360瀏覽器】360安全瀏覽器下載 官方免費版2023 v14.1.1012.0
【360瀏覽器】360安全瀏覽器下載 官方免費版2023 v14.1.1012.0 【優酷下載】優酷播放器_優酷客戶端 2019官方最新版
【優酷下載】優酷播放器_優酷客戶端 2019官方最新版 騰訊視頻播放器2023官方版
騰訊視頻播放器2023官方版 【下載愛奇藝播放器】愛奇藝視頻播放器電腦版 2022官方版
【下載愛奇藝播放器】愛奇藝視頻播放器電腦版 2022官方版 2345加速瀏覽器(安全版) V10.27.0官方最新版
2345加速瀏覽器(安全版) V10.27.0官方最新版 【QQ電腦管家】騰訊電腦管家官方最新版 2024
【QQ電腦管家】騰訊電腦管家官方最新版 2024 360安全衛士下載【360衛士官方最新版】2023_v14.0
360安全衛士下載【360衛士官方最新版】2023_v14.0